Yesterday Davd Coffey published a fascinating piece in which he asked the question – “Whose fault is it that you aren’t good at math?”:
http://deltascape.blogspot.com/2014/10/whose-fault-is-it-that-you-arent-good.html
At the end of his piece he challenges the reader to rewrite two paragraphs from another blog just as he did for his piece. I wanted to take that challenge but found that Coffey’s single sentence “It’s because of your experiences” pretty much captured everything that I was going to say. Damn those clear and concise writers! So, I’ll have to take an incomplete on the specific challenge but want to respond in a different way instead.
I think that most people in the US do not have a great connection with math. There are probably millions of different reasons, but I do think that Coffey’s idea is right on – most people’s experience with math doesn’t leave them wanting to learn more about it or even study it for one minute more than they have to. From where I sit, though, that seems like such a shame.
There is some good news, though. If you really do want to have a better experience with math there are all sorts of things right at your fingertips these days. In fact, if you are looking to have some positive experiences with math there’s probably never been a better time than right now to find them. My response to Coffey’s challenge will be to point out a few that I’ve run across lately.
Actually I’ve picked 10 items from the last couple of years that I’ve either really enjoyed or found to be incredibly important to learn more about. There are three examples from academic math, three from work / industry, three from education, and I’ll end by talking about a sometimes politically hot idea where some school math can provide important information and insight.
First up – Academia
(Academic 1) The 2014 Fields Medals
Every four years the Fields Medals are awarded to some of the world’s outstanding young mathematicians. Maybe I was just paying more attention this time around, but a couple of the stories from the 2014 awards were totally captivating. I found Quanta magazine’s profiles of Manjul Bhargava and Maryam Mirzakhani to be particularly fascinating. If you find these two articles to be interesting, I would definitely encourage you to read the profiles of the other two winners as well:
http://www.simonsfoundation.org/quanta/20140812-the-musical-magical-number-theorist/
http://www.simonsfoundation.org/quanta/20140812-a-tenacious-explorer-of-abstract-surfaces/
These two are typical mathematicians in the same way that Roger Federer and Serena Williams are typical tennis players. One difference probably is that Federer and Williams probably don’t get asked “what will I use tennis for?” very often 🙂 It is neat for me to see people doing groundbreaking work in math getting recognition. I believe that math, and academic math especially, hasn’t been so great at communicating with the public. These sorts of articles help make the world of academic math seem much less mysterious.
One of Bhargava’s early papers was made public after the awards were announced. It was an amazing paper about factorials and it was (surprisingly) not super difficult to read (with means it only took a few days for me to get the hang of it). Working through this paper inspired me to play around with Bhargava’s ideas a little more and even stumble on a fun tidbit hiding inside of his factorials analagous to Euler’s identity  .
.
https://mikesmathpage.wordpress.com/2014/08/27/a-fun-surprise-with-eulers-identity-coming-from-manjul-bhargavas-generalized-factorials/
It was exciting for me to play around with some of the early work of one of today’s top mathematicians. I’d guess that Bhargava’s paper has some great research possibilities for students interested in math.
(Academic 2) An shock discovery about prime numbers
There was quite a buzz last year when Yitang “Tom” Zhang of the University of New Hampshire proved a theorem about prime numbers that had been unsolved for 100’s of years. He showed that there were infinitely many prime numbers that had a gap between them of no more than 70,000,000. It is a hard theorem to understand, obviously, but it set the world of math buzzing. Following the publication of Zhang’s result many mathematicians from all over the world worked together in an online “polymath” project and lowered Zhang’s 70,000,000 bound to around 600. A far better description of the theorem and the back story is given in Jordan Ellenberg’s “How not to be Wrong” – itself a great read about math! I tried to talk about the result a little with my kids, too, so they could get just a peek at the kinds of problems that academic mathematicians think about:
https://mikesmathpage.wordpress.com/2014/05/31/prime-gaps-and-a-james-tanton-problem/
Zhang, who was essentially unknown in the math world prior to proving this theorem, became a star following the publication of his theorem and has recently been awarded a MacArthur “Genius” grant. The video interview of him tells an incredible story:
http://www.macfound.org/fellows/927/%20
For me, Zhang’s story of following his dreams through some difficult times and eventually making an incredible breakthrough in mathematics is an incredibly inspiring story.
(Academic 3) Laura Taalman’s 3D printing blog
I had the great fortune of meeting Taalman in person about a month ago. She’s now serving as the mathematican in residence at the Museum of Mathematics in New York City – a super great win for the Museum.
I’d ran across her work online when we bought a 3D printer earlier in the year. She was in the middle of a project in which she was making a new 3d printed object every day for a year. It was (and is) an incredible undertaking:
http://www.makerhome.blogspot.com/2014/08/day-364-customizable-hinged-polyhedra.html
If you search back through the blog you’ll find many fascinating math projects and you’ll also see how to use some basic software to make your own 3D printing models. This project inspired me to explore how 3D printing could help expose kids to ideas in math that they’d not seen before:
https://mikesmathpage.wordpress.com/2014/08/16/3d-printing-and-negative-space/
Taalman’s year long project on 3d printing is one of the most amazing things I’ve ever seen online. As 3d printers become more common in schools I hope more and more people will get to appreciate her work. In the mean time, if you are in the NYC area and have the opportunity to attend one of her 3D printing projects at the Museum of Math – don’t pass it up!
Next up – Work and Industry
(Work 1) One of the most amazing applications of math that I’ve seen recently came from the Rosetta satellite project. The Rosetta spacecraft was launched in 2004 and recently began orbiting a comet if you can believe that! This project is truly one of the greatest scientific accomplishments of the last decade. Recently (or at least I saw it recently) the Rosetta team published a simulation that allows you to see the path that the spacecraft took to intercept the comet:
http://sci.esa.int/where_is_rosetta/
The key to being able to map out the path of the spacecraft ahead of time is a field of math called differential equations. The simulation from the Rosetta team is an absolutely beautiful example of differential equations in action. I remember seeing a much simpler problem from the 1959 Putnam example as a double star (!!) problem in my differential equations book as a kid:
“A sparrow flowing horizontally in a straight line is 50 feet below an eagle and 100 feet above a hawk. Both the hawk and the eagle fly directly towards the sparrow, reaching it at the same time. How far does each bird fly?”
That problem seemed so cool to me and inspired me to want to learn more about differential equations. Mapping out the required path of the spacecraft is a (much!) more complicated version of this problem. I think the Rosetta visual – as well as the pictures coming back from the comet – will inspire kids in the same way the eagle and hawk problem inspired me. Such a beautiful illustration of math in action from the Rosetta team.
(Work 2) In early 2014 Quicken announced that they were offering a $1 billion dollar prize if someone could correctly pick each winning team in every game of the NCAA men’s college basketball tournament. I was lucky to be involved in this promotion and it is one of the most interesting applications of probability that I’ve ever seen. One obvious question is this – what are the odds that someone could pick all of these games correctly in the first place? It is fun to see how the answers to this question change as your assumptions about the likelihood of picking games correctly change. There are other fun questions, too, and even a surprise application of the “birthday paradox” as we wondered about how many people would end up picking the games in exactly the same way.
This project also led to a fun one to talk about with my kids:
https://mikesmathpage.wordpress.com/2014/03/22/perfect-brackets/%20
It isn’t often that some really neat math shows up in my work, so this was a really special treat for me!
(Work 3) The financial crisis –
One of the important things to understand form the financial crisis is how the use and misuse of mathematical models ended up causing severe financial problems. Whether it was the statistical modelling used by the rating agencies to rate mortgage backed securities, the modeling used by regulators to measure what would happen in “stress” situations, or the modelling used by the buyers and sellers of securities, the modelling missed by a mile.
It was hardly the first time math had gone horrible wrong in the financial markets. Roger Lowenstein’s excellent book “When Genius Failed” details some of the flaws in the models that were used in the financial markets in the late 1990s. This time wasn’t different! Next time won’t be different either and these lessons about not understanding correlation, gap risk, or simply that it is impossible to model human behavior are forgotten quickly. The more deal hungry people get, the faster the lessons are forgotten. This tweet from Nassim Taleb from October 8, 2014 sums up some of the modelling problems well as anything I can offer:
https://twitter.com/nntaleb/status/519841458657198080
What should really concern people, though, is not just that the failures in the modeling are nearly forgotten, but these fun little complicated models are creeping away from the financial markets into other areas. Cathy O’Neil (a mathematician with experience in the financial markets) writes about these models occasionally on her blog. Here’s one of her pieces on the the use of statistical models to measure teacher performance:
Why Chetty’s Value-Added Model studies leave me unconvinced
If you want to understand how people are trying to either measure or mislead with models, it is important to understand the math behind those models. As these models continue to creep and creep into all aspects of life, understanding how they work will become even more important.
Next up – Education
(Education 1) I think there are plenty of examples from both theory and practice that are not part of a standard curriculum that kids will find interesting and engaging. I try as hard as I can to create fun discussions with my kids using as many of these examples as I can find. Two of my favorites from the last year involve Graham’s number and infinite series.
I’d never heard of Graham’s number until I saw a tweet about it from Evelyn Lamb. After researching it a little bit I found a cool Numberphile video about Graham’s number. Trying to understand this number will change the way you think about numbers – would you have ever thought there could be a number that was so big that it was basically impossible to even talk about how big it was? A neat break from typical arithmetic for sure:
https://mikesmathpage.wordpress.com/2014/04/12/an-attempt-to-explain-grahams-number-to-kids/
One other fun example that is really pure theory came from Jordan Ellenberg’s book “How Not to be Wrong.” In that book he talks through a concept he calls “algebraic intimidation.” The specific example he uses is the typical proof that 0.99999.. [repeating forever] = 1. I tried out some of his “intimidation” examples with my kids and they loved it:
https://mikesmathpage.wordpress.com/2014/09/24/jordan-ellenbergs-algebraic-intimidation/
As I wrote above, people love to use models to justify their positions. A lot of that justification is just like Ellenberg’s “algebraic intimidation.” It is important to learn early on not to be intimidated by math.
(Education 2) Social media turns out to be a great way to learn from math educators. I’m constantly surprised by how many ideas / lessons / problems / and other(!) get shared on blogs and on twitter, for example. When it comes to teaching my own kids Fawn Nguyen has been a constant source of ideas and inspiration. Here’s a fun problem she shared just a month ago:
https://mikesmathpage.wordpress.com/2014/09/03/fawn-nguyen-shares-a-really-neat-math-forum-problem/
and if you want something for kids that is as far away from “do problems 1 – 50 in your algebra book” as you can get, check out Fawn’s Visual Patterns website:
http://www.visualpatterns.org/%20
You might just find yourself exploring patters 1 through 50 just for fun!!
(Education 3) Another teacher who’s online contributions leave you wondering “how do you find the time?” is Patrick Honner from New York City. His critical reviews of some of the NY state math exams are important reading for anyone interested in learning about the testing culture we all seem to live in:
http://mrhonner.com/regents-recaps%20
Away from the exam reviews, when you see his thoughts and ideas about interesting math (and, in particular, math that will be interesting for students) you can’t help but get caught up in the excitement. Take his “proof without words” showing the sum of a neat infinite series, for example:
https://mikesmathpage.wordpress.com/2013/12/21/numberphiles-pebbling-the-chessboard-game-and-mr-honners-square/
Going back to what inspired this blog post in the first place. If you are wondering about how to get excited about math, or how to find some great math experiences, it is hard to think of a better starting place on line than simply following both Fawn Nguyen and Patric Honner on twitter.
(Last) The final example – Pensions
An often controversial topic where math is essential to understanding the economic issues is pensions, and funding of pensions in particular. This tweet from yesterday got me thinking about using this topic as an example:
One thing that makes understanding pensions particularly difficult is that seemingly small changes in assumptions produce large changes in the economics. From the math point of view, though, the math that explains that isn’t all that hard The example I’ll use below just involves the polynomial:

Don’t fall for my attempt at algebraic intimidation,though, a much better representation of this polynomial is the factored form 
With a pension someone promises to make a payment, say, 25 years from now as part of your retirement. In order to fulfill that promise that someone (likely a corporation or a municipal entity) either needs to set aside some money today or put aside some money over time. But how much?
Lots of entities think that they can earn 8% per year on their investments, so the question of how much money to set aside today boils down to finding out how much money $1 turns into in 25 years if you earn 8% per year. It turns out that you can just evaluate the polynomial above at x = 8%, so  , which is approximately 6.85. Alternately, if you’ve promised to pay $100 25 years from now and you think you can earn 8% per year on your investments, simply divide $100 by 6.85 to see how much you need to set aside on day 1. This math tells you that you need to set aside about $14.60 on day 1 to “fully fund” that future $100 payment under the 8% growth assumption.
, which is approximately 6.85. Alternately, if you’ve promised to pay $100 25 years from now and you think you can earn 8% per year on your investments, simply divide $100 by 6.85 to see how much you need to set aside on day 1. This math tells you that you need to set aside about $14.60 on day 1 to “fully fund” that future $100 payment under the 8% growth assumption.
But let’s say that you think you can only earn 6% on your money instead of 8% – how much should you set aside to cover that $100 in 25 years now? Take a guess first, because the answer is surprising.
We look at  here and find a value of roughly 4.29. Taking $100 / 4.29 we get $23.31 this time – an increase of roughly 60% in the amount of money we need to set aside on day 1 to cover the promise. Amazing how much the values change with a seemingly small change in growth rate! How could the difference between earning 8% annually and 6% annually be so large?
here and find a value of roughly 4.29. Taking $100 / 4.29 we get $23.31 this time – an increase of roughly 60% in the amount of money we need to set aside on day 1 to cover the promise. Amazing how much the values change with a seemingly small change in growth rate! How could the difference between earning 8% annually and 6% annually be so large?
As I write this, 25 year “risk free” rates in the US are about 3.2%. You need to set aside about $45.45 if you think you can earn the risk free rate.
So, should you worry about all of these growth rate assumptions in pensions? Well, people like to assume they can invest and earn lots more than the “risk free” rate. They sort of doubly like to assume that when it means that they can put less money aside to cover those future obligations. They triply like it when the consequences of being wrong occur when they are long gone. Sort of a financial and political free lunch.
But there are serious questions. For example, how much risk should you be taking when you are investing people’s retirement money? Most people bristle at the suggestion of Social Security money being invested in the stock market, but few seem to be bothered by the fact that billions and probably trillions of dollars of pension money are invested both in the stock market and in other sorts of private investments like hedge funds.
If all of the other fun examples I’ve given above aren’t enough to get you interested in math, hopefully getting a better understanding of your own financial future will serve as good motivation. The math – just a little bit of polynomials and maybe exponentials if you want to get slightly more tricky – is maybe not as interesting as some of the other math mentioned above, but trillions of dollars in retirement money hinges on that math. Your own retirement might, too. It certainly is a good enough example, I think, to refute the idea that there are no important applications of expanding and factoring polynomials 🙂
So, to wrap up – sorry to David Coffey for turning a two paragraph challenge into 2000 words. I hope, though, that someone asking themselves the question about their own math ability is able to find positive experiences with math. There are so many great examples out there these days, and so many different directions that those examples can take you. I do think that everyone will find a fun little positive experience if they are determined to look around long enough.



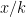 , so you are getting “x” times the loss cost.
, so you are getting “x” times the loss cost. 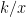 trials to collect enough money to pay a single loss. The probability of not paying out in the first
trials to collect enough money to pay a single loss. The probability of not paying out in the first  =
= 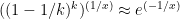 since k is large.
since k is large.  , and
, and 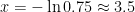



 < 2) from a data set, you will likely underestimate it.
< 2) from a data set, you will likely underestimate it. 

