ot likely to be all that coherent as I threw this together during my son’s archery class, but I just wanted to get some ideas out of my head and on to paper . . . .
Some work from Nassim Taleb has been really inspirational for me in the last few years and I’m now trying to try to understand a few statistical ideas he’s shared a bit more carefully.
The kick in the pants that led to this post was seeing Taleb’s interview about the Peters and Gell-Mann paper earlier in the week. Here is the short discussion on Twitter that caught my attention.
I’d read both the paper and also (one of) Taleb’s take(s) on it last year:
The Logic of Risk Taking by Nassim Taleb
Unfortunately, though, the paper had drifted out of my mind so I’m happy to have been reminded of it.
I’m sort of stumbling around in the dark trying to figure out the best way to understand some of the ideas, but the starting point I’ve chosen is Thorp’s paper from 1969 on Optimal Gaming Systems:
Optimal Gambling Systems for Favorable Games by E. O. Thorpe
Questions that are on my mind that I hope will be at least partially resolved by this project relate to:
(1) Zvi Bodie’s “On the risk of stocks in the long run” paper
On the Risk of Stocks in the Long Run by Zvi Bodie
I like this paper because Bodie asks and answers a very easy to understand question – how much does it cost to insure that a portfolio earns at least the risk-free rate over various time horizons?
The (surprise) answer is that the cost of insurance rises over time and eventually (essentially) equals the present value of the maximum exposure.
The result has become less surprising to me over time, but one reason I like going back to this paper is that both the math behind the question and math behind the result are relatively easy to understand.
So, 20 years after seeing the Bodie paper for the first time, I’m wondering if the Peters and Gell-Mann paper will give me a new way of understanding the result in Bodie’s paper?
In may different fields – not just finance – there is an implicit assumption that risk declines over time. The Peters / Gell-Mann paper seems to refute that idea.
(2) Pricing of options with and without collateral
One problem that I have never been able to resolve in my mind relates to the right way to think about the difference in price between collateralized and uncollateralized options.
So, take a specific example. Suppose that the price for a 15 year European style put on the S&P500 with daily cash margin requirements is $27 for each $100 of notional. Now, your friendly bank counterparty says that instead of $27 they will pay you $20, but you will not have to ever post collateral and they will just come back in 15 years and let you know how much money you owe under the contract (which, of course, might be $0 if the S&P500 is higher 15 years from now than it is today).
Which is a better deal?
The relationship (at least in my mind) between this question and the Peters / Gell-Mann paper comes from another of Taleb’s papers:
Click on “The Mathematical Foundations of Precaution”
The idea I want to highlight is “Principle 1” at the beginning of section II:
“A unit needs to take any risk as if it were going to take it repeatedly – at a specified frequency – over its remaining lifespan.”
The contract with daily margin requirements essentially repeats the same risk daily for 15 years. The uncollatearlized one, though, really does have only one decision and repetition here would occur only every 15 years. I’ve never figured out a good way to estimate the correct price difference in general, though, and basically have to start from scratch every time.
(3) A pricing mechanism for simple risks
Back in the early 2000s I came up with a very simple pricing heuristic for one-off risks. The idea that you need to take risks as if they were going to happen repeatedly reminds me of that old, back of the envelope pricing mechanism.
My idea was to imagine taking the bet over time and look at the probability that you would collect enough money to pay one loss before the first loss actually happened.
Assume for simplicity that your payout will be $1.
Probability of loss -> 

Premium collected each time -> 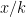
It will thus take you 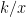

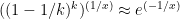
One surprise is that the the result is independent of
This simple formula tells you that if you want a 50% chance of collecting enough money to pay a claim before you have to pay it no need to charge roughly 1.5x the expected loss cost. For a 75% chance you need 3.5x the loss cost, and for a 90% chance you need about 10x. The cost for safety rises quickly.
I think this result is at least consistent with the ideas in the Peters / Gell-Mann paper. I’d love to be able to expand the ideas to situations where the probability of loss isn’t so easy to calculate.
(4) One other area where there are different views of expectation
I don’t think there is a direct connection between the ideas in the Peters and Gell-Mann paper, but there is another pretty famous case where different views of expectation produce different answers:
The “average number of friends” or “average class size” idea is just a reminder that even seemingly simple situations can have different sets of statistics depending on how you view the situation.
