Two weeks ago I saw an amazing piece of work by John Shonder shared on Twitter:
I’ve already done two projects with the boys using Shonder’s ideas. The first was just walking through his code and showing him that the underlying ideas weren’t that complicated:
Using John Shonder’s Amazing US Temperature visualization wtih kids
At the end of that project I asked the boys for follow up ideas. My younger son (in 7th grade) thought it would be interesting to look at percent change rather than raw temperature change. We did that follow up yesterday:
Follow up #1 to John Shonder’s US temperature change visualizaiton
My older son (in 9th grade) thought it would be interesting to see if we could use the data to make predictions about future temperatures. We looked at that idea today.
Since an even cursory discussion of predictions is way more complicated than I’d like a 15 min talk with a 7th grader and an 9th grader to be, I decided to focus more on best fit curves rather than on actual predictions.
A funny side note to this discussion is that when I told my older son about this change he said – “That sounds pretty hard.” I told him not to worry, that there was a Mathematica command that does the fitting. His response was “of course there is” – ha ha.
So, we started today’s project by looking at plots of some of the county average temperature data. One thing I did here was have the boys estimate what a best fit line would look like by placing a ruler on the computer screen:
Next we used Mathematica to find the best fit line to the data and used Shonder’s code to do a county by county visualization of the slope of that best fit line.
Not too surprisingly, this visualization looked a lot like Shonder’s original one and the percent change one we looked at yesterday. The fact that all three of these visualization looked pretty similar led to a nice discussion about why that wasn’t so surprising:
Next we fit with a quadratic function rather than a line. As with the fit to the line, we looked a several counties first to get a feel for what was going on:
Finally, we did a county by county visualization of the 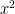
I’ve really enjoyed the discussions that we’ve had using Shonder’s project. It is amazing to me how Mathematica (and Shonder’s terrific code!) makes a pretty difficult data analysis project accessible to kids.

If you get into curve fitting you should talk about what assumptions are baked into the “least squares” criterion, namely, that the errors on the measurements are independent Gaussians. Which is reasonable if you think that there are many roughly independent sources of error, and apply the Law of Large Numbers.
When I was thinking about what to cover in this project, thinking about the rabbit hole of assumptions in curve fitting was one of the reasons I decided to take a much higher level approach. My guess is those details are pretty hard for kids to appreciate, I think anyway, and putting the rule on the screen seemed to show that their intuition was close enough to the best fit lines.
The one detail I was hoping my older son would appreciate (since we just did a calculus course) was that fitting with an exponential and fitting with a quadratic were not so different.